publications
research publications in reversed chronological order. An up-to-date list is available on Google Scholar.
2023
-
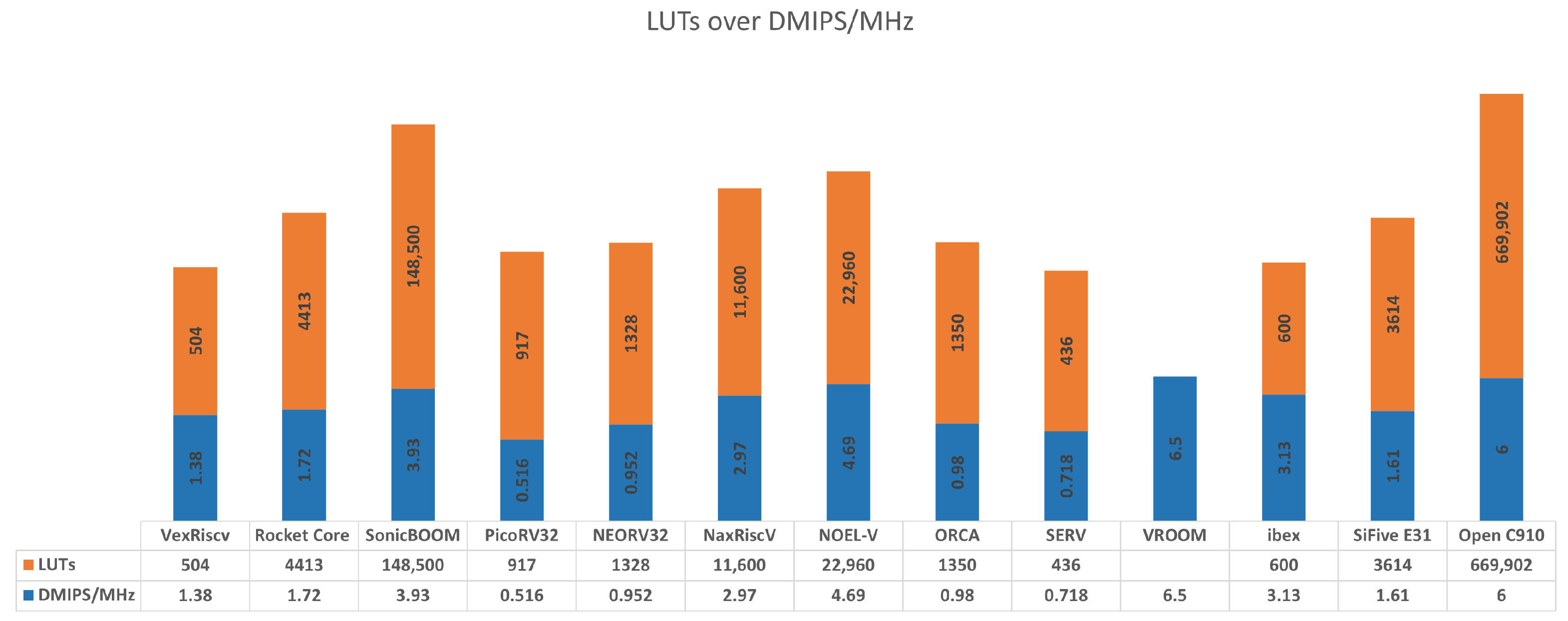 A Survey on RISC-V-Based Machine Learning EcosystemStavros Kalapothas , Manolis Galetakis , Georgios Flamis , and 2 more authorsInformation, 2023
A Survey on RISC-V-Based Machine Learning EcosystemStavros Kalapothas , Manolis Galetakis , Georgios Flamis , and 2 more authorsInformation, 2023In recent years, the advancements in specialized hardware architectures have supported the industry and the research community to address the computation power needed for more enhanced and compute intensive artificial intelligence (AI) algorithms and applications that have already reached a substantial growth, such as in natural language processing (NLP) and computer vision (CV). The developments of open-source hardware (OSH) and the contribution towards the creation of hardware-based accelerators with implication mainly in machine learning (ML), has also been significant. In particular, the reduced instruction-set computer-five (RISC-V) open standard architecture has been widely adopted by a community of researchers and commercial users, worldwide, in numerous openly available implementations. The selection through a plethora of RISC-V processor cores and the mix of architectures and configurations combined with the proliferation of ML software frameworks for ML workloads, is not trivial. In order to facilitate this process, this paper presents a survey focused on the assessment of the ecosystem that entails RISC-V based hardware for creating a classification of system-on-chip (SoC) and CPU cores, along with an inclusive arrangement of the latest released frameworks that have supported open hardware integration for ML applications. Moreover, part of this work is devoted to the challenges that are concerned, such as power efficiency and reliability, when designing and building application with OSH in the AI/ML domain. This study presents a quantitative taxonomy of RISC-V SoC and reveals the opportunities in future research in machine learning with RISC-V open-source hardware architectures.
@article{info14020064, author = {Kalapothas, Stavros and Galetakis, Manolis and Flamis, Georgios and Plessas, Fotis and Kitsos, Paris}, title = {A Survey on RISC-V-Based Machine Learning Ecosystem}, journal = {Information}, volume = {14}, year = {2023}, number = {2}, article-number = {64}, url = {https://www.mdpi.com/2078-2489/14/2/64}, issn = {2078-2489}, doi = {10.3390/info14020064} } -
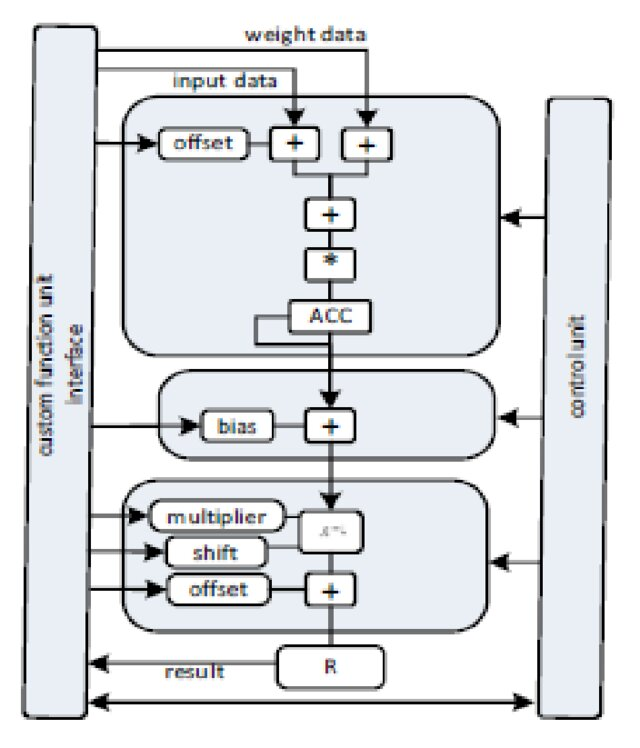 Design and implementation of a compact RISC-V based Machine Learning accelerator on Low End FPGAManolis Galetakis , Stavros Kalapothas , Georgios Flamis , and 2 more authorsIn Proceedings & Highlights - Emerging Tech Conference Edge Intelligence 2023 , Oct 2023
Design and implementation of a compact RISC-V based Machine Learning accelerator on Low End FPGAManolis Galetakis , Stavros Kalapothas , Georgios Flamis , and 2 more authorsIn Proceedings & Highlights - Emerging Tech Conference Edge Intelligence 2023 , Oct 2023In recent years, the use of Machine Learning (ML) algorithms on edge devices for common applications such as computer vision, speech recognition etc. is increasing rapidly. With the evolution and the complexity of the latest ML models, inference has become more computationally expensive and therefore, deployment to resource-constraint edge devices is a challenging task. A common technique to address that challenge and increase performance and efficiency, is to offload compute intensive functions from software and run them onto dedicated hardware instead. In this paper we present the complete flow of software-hardware co-design for a lightweight object detection ML model, first time implemented on a RISC-V soft processor. Then we describe software optimizations for the model and a compact hardware accelerator design. We deploy and profile, in terms of cycle count, resource utilization and power consumption of our design on a Xilinx Artix7 35T low-end Field Programmable Gate Array (FPGA) device. Our RISC-V based compact accelerator achieves almost 3.7x inference speedup @ 180 mW power consumption and consumes 5.5K slice LUTs (26.41%) – 4.3K slice registers (10.19%). Therefore, our implementation facilitates object detection for a variety of non-speed demanding embedded applications, at competent speed on small– entry-level FPGA devices.
@inproceedings{Galetakis2026-jz, title = {Design and implementation of a compact {RISC-V} based Machine Learning accelerator on Low End FPGA}, booktitle = {Proceedings \& Highlights - Emerging Tech Conference Edge Intelligence 2023}, author = {Galetakis, Manolis and Kalapothas, Stavros and Flamis, Georgios and Kitsos, Paris and Plessas, Fotis}, url = {https://conference.hetia.org/publications/design-and-implementation-of-a-compact-risc-v-based-machine-learning-accelerator-on-low-end-fpga/}, publisher = {Hellenic Emerging Technology Industry Association}, pages = {158-165}, month = oct, year = {2023}, conference = {Emerging Tech Conference Edge Intelligence 2023}, doi = {10.63438/GSRA5108} }


2022
-
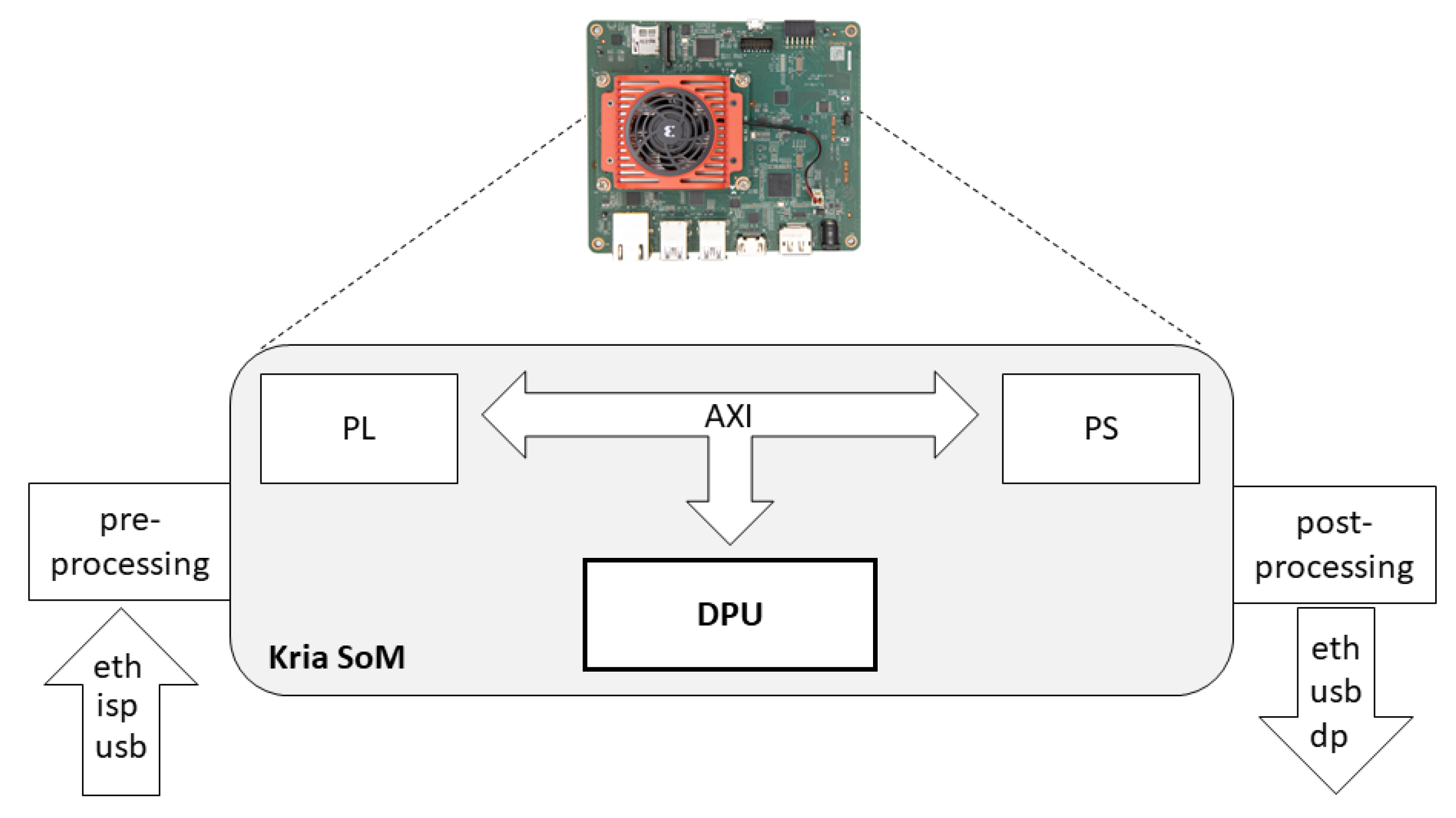 Efficient Edge-AI Application Deployment for FPGAsStavros Kalapothas , Georgios Flamis , and Paris KitsosInformation, Oct 2022
Efficient Edge-AI Application Deployment for FPGAsStavros Kalapothas , Georgios Flamis , and Paris KitsosInformation, Oct 2022Field Programmable Gate Array (FPGA) accelerators have been widely adopted for artificial intelligence (AI) applications on edge devices (Edge-AI) utilizing Deep Neural Networks (DNN) architectures. FPGAs have gained their reputation due to the greater energy efficiency and high parallelism than microcontrollers (MCU) and graphical processing units (GPU), while they are easier to develop and more reconfigurable than the Application Specific Integrated Circuit (ASIC). The development and building of AI applications on resource constraint devices such as FPGAs remains a challenge, however, due to the co-design approach, which requires a valuable expertise in low-level hardware design and in software development. This paper explores the efficacy and the dynamic deployment of hardware accelerated applications on the Kria KV260 development platform based on the Xilinx Kria K26 system-on-module (SoM), which includes a Zynq multiprocessor system-on-chip (MPSoC). The platform supports the Python-based PYNQ framework and maintains a high level of versatility with the support of custom bitstreams (overlays). The demonstration proved the reconfigurabibilty and the overall ease of implementation with low-footprint machine learning (ML) algorithms.
@article{info13060279, author = {Kalapothas, Stavros and Flamis, Georgios and Kitsos, Paris}, title = {Efficient Edge-AI Application Deployment for FPGAs}, journal = {Information}, volume = {13}, year = {2022}, number = {6}, article-number = {279}, url = {https://www.mdpi.com/2078-2489/13/6/279}, issn = {2078-2489}, doi = {10.3390/info13060279} } -
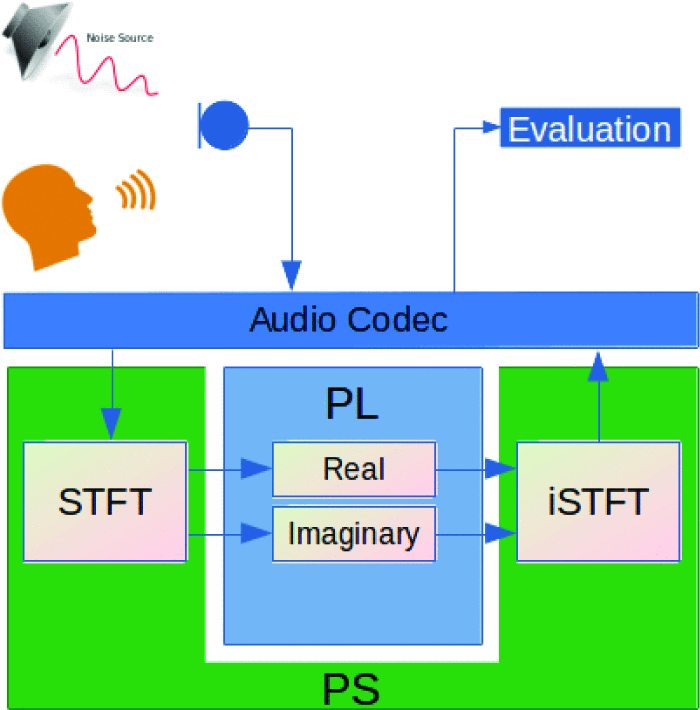 FPGA-SoC Deployment of Complex Deep Neural Network for Magnitude and Phase Computations in Denoising of Speech SignalGeorgios Flamis , Stavros Kalapothas , and Paris KitsosIn 2022 IFIP/IEEE 30th International Conference on Very Large Scale Integration (VLSI-SoC) , Oct 2022
FPGA-SoC Deployment of Complex Deep Neural Network for Magnitude and Phase Computations in Denoising of Speech SignalGeorgios Flamis , Stavros Kalapothas , and Paris KitsosIn 2022 IFIP/IEEE 30th International Conference on Very Large Scale Integration (VLSI-SoC) , Oct 2022@inproceedings{9939632, author = {Flamis, Georgios and Kalapothas, Stavros and Kitsos, Paris}, booktitle = {2022 IFIP/IEEE 30th International Conference on Very Large Scale Integration (VLSI-SoC)}, title = {FPGA-SoC Deployment of Complex Deep Neural Network for Magnitude and Phase Computations in Denoising of Speech Signal}, year = {2022}, volume = {}, number = {}, pages = {1-5}, keywords = {Deep learning;Costs;Neural networks;Noise reduction;Computer architecture;Speech enhancement;Very large scale integration;speech enhancement;complex spectrogram;phase processing;deep neural network;reconstruction}, doi = {10.1109/VLSI-SoC54400.2022.9939632} }


2021
-
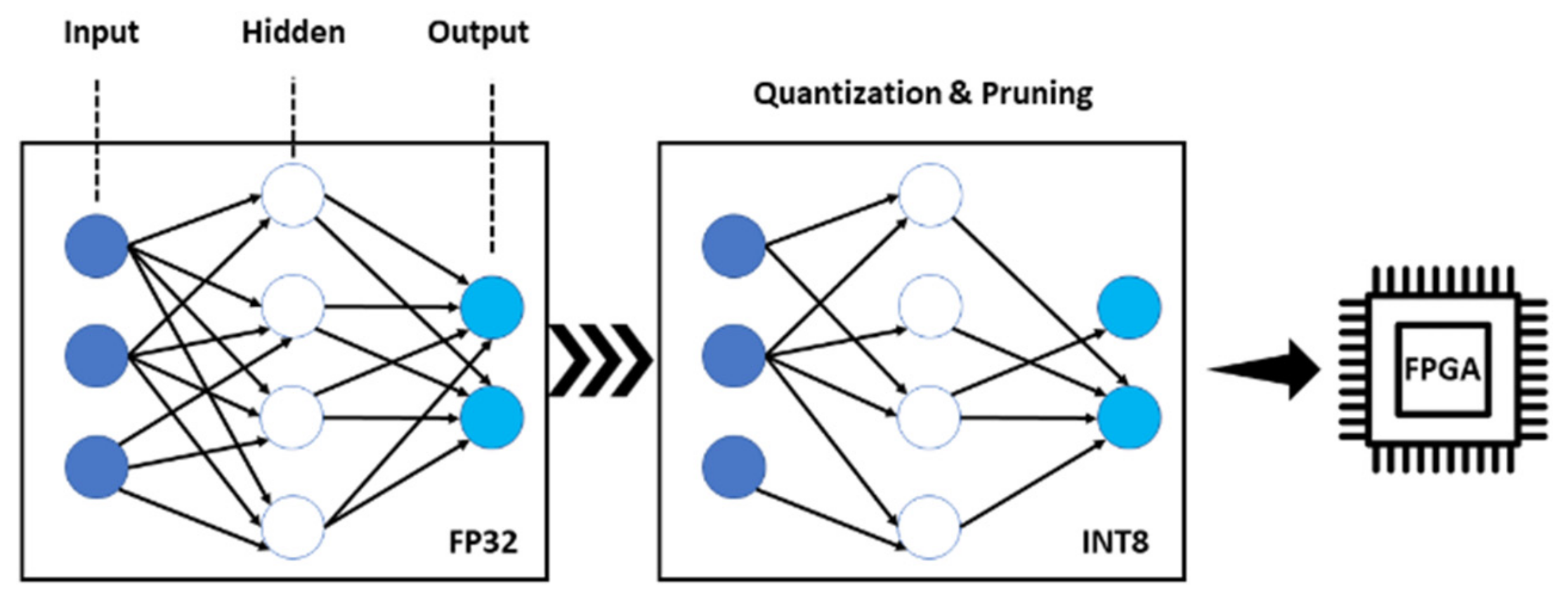 Best Practices for the Deployment of Edge Inference: The Conclusions to Start DesigningGeorgios Flamis , Stavros Kalapothas , and Paris KitsosElectronics, Oct 2021
Best Practices for the Deployment of Edge Inference: The Conclusions to Start DesigningGeorgios Flamis , Stavros Kalapothas , and Paris KitsosElectronics, Oct 2021The number of Artificial Intelligence (AI) and Machine Learning (ML) designs is rapidly increasing and certain concerns are raised on how to start an AI design for edge systems, what are the steps to follow and what are the critical pieces towards the most optimal performance. The complete development flow undergoes two distinct phases; training and inference. During training, all the weights are calculated through optimization and back propagation of the network. The training phase is executed with the use of 32-bit floating point arithmetic as this is the convenient format for GPU platforms. The inference phase on the other hand, uses a trained network with new data. The sensitive optimization and back propagation phases are removed and forward propagation is only used. A much lower bit-width and fixed point arithmetic is used aiming a good result with reduced footprint and power consumption. This study follows the survey based process and it is aimed to provide answers such as to clarify all AI edge hardware design aspects from the concept to the final implementation and evaluation. The technology as frameworks and procedures are presented to the order of execution for a complete design cycle with guaranteed success.
@article{electronics10161912, author = {Flamis, Georgios and Kalapothas, Stavros and Kitsos, Paris}, title = {Best Practices for the Deployment of Edge Inference: The Conclusions to Start Designing}, journal = {Electronics}, volume = {10}, year = {2021}, number = {16}, article-number = {1912}, url = {https://www.mdpi.com/2079-9292/10/16/1912}, issn = {2079-9292}, doi = {10.3390/electronics10161912} } -
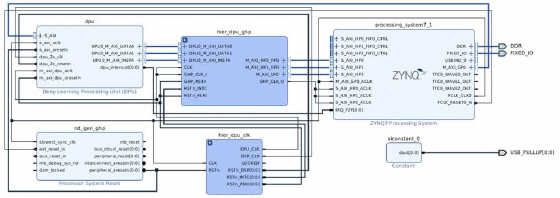 Workflow on CNN utilization and inference in FPGA for embedded applications: 6th South-East Europe Design Automation, Computer Engineering, Computer Networks and Social Media Conference (SEEDA-CECNSM 2021)Georgios Flamis , Stavros Kalapothas , and Paris KitsosIn 2021 6th South-East Europe Design Automation, Computer Engineering, Computer Networks and Social Media Conference (SEEDA-CECNSM) , Oct 2021
Workflow on CNN utilization and inference in FPGA for embedded applications: 6th South-East Europe Design Automation, Computer Engineering, Computer Networks and Social Media Conference (SEEDA-CECNSM 2021)Georgios Flamis , Stavros Kalapothas , and Paris KitsosIn 2021 6th South-East Europe Design Automation, Computer Engineering, Computer Networks and Social Media Conference (SEEDA-CECNSM) , Oct 2021@inproceedings{9566259, author = {Flamis, Georgios and Kalapothas, Stavros and Kitsos, Paris}, booktitle = {2021 6th South-East Europe Design Automation, Computer Engineering, Computer Networks and Social Media Conference (SEEDA-CECNSM)}, title = {Workflow on CNN utilization and inference in FPGA for embedded applications: 6th South-East Europe Design Automation, Computer Engineering, Computer Networks and Social Media Conference (SEEDA-CECNSM 2021)}, year = {2021}, volume = {}, number = {}, pages = {1-6}, keywords = {Training;Performance evaluation;Computational modeling;Wearable computers;Tools;Software;Time measurement;FPGA;CNN;embedded;MNIST;execution time;performance}, doi = {10.1109/SEEDA-CECNSM53056.2021.9566259} } -
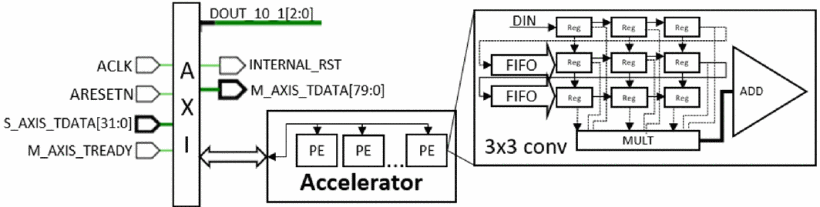 Importing Custom DNN Models on FPGAsStavros Kalapothas , Georgios Flamis , and Paris KitsosIn 2021 10th Mediterranean Conference on Embedded Computing (MECO) , Oct 2021
Importing Custom DNN Models on FPGAsStavros Kalapothas , Georgios Flamis , and Paris KitsosIn 2021 10th Mediterranean Conference on Embedded Computing (MECO) , Oct 2021@inproceedings{9460248, author = {Kalapothas, Stavros and Flamis, Georgios and Kitsos, Paris}, booktitle = {2021 10th Mediterranean Conference on Embedded Computing (MECO)}, title = {Importing Custom DNN Models on FPGAs}, year = {2021}, volume = {}, number = {}, pages = {1-4}, keywords = {Machine learning algorithms;Computational modeling;Neural networks;Software algorithms;Transforms;Tools;Hardware;deep neural networks (DNNs);deep learning (DL);fpga;vhdl}, doi = {10.1109/MECO52532.2021.9460248} }


